목차
- CNN의 역사
- Fully Connected Layer의 문제점
- CNN의 전체 구조
- Convolution & Correlation
- Receptive Field
- Pooling
- Visualization
- Backpropagation
- Reference
1. CNN의 역사
- 1989년 LeCun이 발표한 논문 "backpropagation applied to handwritten zip" 에서 처음으로 소개됨
- 2003년 Behnke의 논문 "Hierachical Neural Network for image interpretation"을 통해서 일반화가 됨
- 2003년 Simard의 논문 "Best practices for convolutional neural networks applied to visual document analysis"을 통해서 단순화 됨
- 그 이후, GP GPU(General Purpose GPU)를 통해서 CNN을 구현할 수 있는 방법이 소개됨
- DBN(Convolutional Deep Belief Networks for Scalable Unsupervised Learning of Hirarchical Representations) 등 많은 분야에서 활발하게 연구 및 진행 중
2. Fully Connected Layer의 문제점
기존에 Image 인식에 사용하는 Fully Connected Neural Network의 작동방식은 Image를 pixel의 행(rows)을 직렬화(serialization)한 후,
이를 입력신호로 주게 된다.
직렬화 방법에 대한 부분은 Keras에서 Fully Connected Layer로 MNIST 데이터를 인식하는 예제(추후 게시 예정)를 참고하면 이해에 도움이 될 수 있다.
아래 그림을 보면 width, height가 각각 16인 이미지는 총 16*16 = 256개의 입력신호로 직렬화되서 들어가게 된다.
Fully Connected Layer는 이를 이용하여 Classification을 학습하고 수행하게 된다.
이러한 Fully Connected Layer는 Image를 입력데이터로 했을 때, 몇가지 문제점을 가지게 된다.
- Image가 고해상도가 될 경우 input neuran이 급격하게 증가하게 되어, parameter의 수가 급격하게 증가하게 된다.
(아래의 그림의 경우 input neuran 256개와 1개의 layer에서 100개의 hidden neuran을 사용하면, parameter의 개수는 총 28326개가 된다.) - 영상의 특성상 특정 pixel은 주변 pixel과 관련이 있는데(locality) Fully Connected Layer의 input neuran에 입력신호를 넣기 위해 직렬화(serialization)을 수행하면서 이러한 상관관계(locality)를 잃게된다.
- Fully Connected Layer는 영상의 전체 관계(topology)를 고려하지 못하게 되어, 입력 데이터의 변형에 매우 취약하게 된다.
- 변형에 취약한 Fully Connected Layer는 변형된 영상의 학습데이터를 굉장히 많이 요구하게 된다(crop, shift, noise, rotate 등등 data augmentation)
- 이러한 부분은 학습량과 수많은 학습데이터, 수많은 parameter를 요구하게 되어, 영상을 대상으로 하는 Neural Network의 학습을 기대하기 어렵게 만든다.

3. CNN의 구조
CNN의 자세한 부분을 살펴보기 전에, 전체 그림을 보기 위해 CNN의 구조를 먼저 살펴보고 가겠다.

- Receptive Field를 통해서 feature map을 생성한다.
- Pooling을 이용하여 Sub-sampling 혹은 Down Sampling을 진행한다.
- 설계자의 설계에 따라 1번과 2번을 반복한다. (2번은 생략될 수 있다.)
- 이를 직렬화하여 Fully Connected Layer로 입력한다.
- Fully Connected Layer를 통해서 해당 Image에 대한 Classification 결과를 얻는다.
4. Convolution과 Correlation












") | ") |
") |










5. Receptive Field
일반적으로 영상처리에 Convolutional Kernel이라고 불리는 것이 있다.
아래와 같은 그림이 바로 Convolutional Kernel이다.

CNN에서는 저기에 있는 Convolutional Kernel의 계수 모두가 Weights로 이루어진 것을 Receptive Field라고 한다.
Receptive Field의 계수는 모두 Weights로 구성되어있기 때문에 CNN의 Backpropagation을 통해서 모두 학습될 수 있다.
따라서 CNN은 해당 영상에 대해서 좀 더 적합한 Feature를 찾도록 학습된다.
CNN이 Convolutional Neural Network라고 불리고 있지만, 실질적으로 Feed-Forward할 때와 BackPropagation 할 때,
수식이 뒤집어지기때문에, Feed-Forward를 Convolution을 한다면 Backpropagation에서는 Correlation을
Feed-Forward가 Correlation이라면 Backporpation에서는 Correlation을 사용한다.
아래에서 Correlation이라는 개념으로 Feed-Forward를 보게 되면, 해당 이미지에 다음과 같은 Kernel을 Correlation을하게되면
Kernel과 Image의 특징이 유사하기 때문에 높은 값(Value)가 나온다.
이런 개념으로 Receptive Field는 해당 이미지에서 학습된 Kernel의 특징이 해당 Image에 있는지 없는지 확인하는 용도로 쓰인다.

상단의 이미지의 경우에 Kernel과 Image가 특징이 일치하기 때문에 높은 Value가 나오겠지만
하단의 이미지의 경우에는 Kernel과 Image의 특징이 일치하지 않기 때문에 낮은 Value가 나온다.
이게 Convolutional Network가 Image를 인식하는 기본적인 원리가 된다.


영상처리에서는 원본 영상에서 Convolutional Kernel을 하나 곱해서 하나의 새로운 영상을 만들어 내는데, 이를 CNN에서는 Feature map을 생성한다고 한다.
CNN에서는 이러한 Receptive Field를 여러개 쓰며, 그에 따라 나오는 Feature map도 여러개로 나타나게 된다.
그래서 일반적으로 CNN에서 표현하는 딮러닝 아키텍쳐에 대한 도식도는 다음과 같은 그림을 많이 볼 수 있게 된다.

해당 그림에서는 Receptive Field를 도식화하진 않았으나, 나오는 Feature Map의 차원(Dimension)을 이용해서 유추가 가능하다.
일반적으로 Receptive Field가 도식화된다면, 정육면체가 될 것이다.
Padding
영상처리에서도 OpenCV나 기타 라이브러리를 단순히 쓰는게 아니라, 직접 Convolution Kernel을 사용해서 native하게 코드를 작성하게 되면,
Convolutional Kernel을 원본 Image에 Convolution했을 때, 결과 이미지가 원본 이미지보다 작은 이미지가 나오는 것을 알 수 있다.

그 이유는 원본 Image에 어느 한 pixel에 Convolution을 적용하게 되면 Convolution kernel의 중앙이 해당 pixel에 위치하게 되는데,
이렇게 되면, 원본 영상의 외곽 부분은 Convolution kernel이 영상 크기 밖으로 나오기 때문이다. 이렇게 Image가 작아지는데 CNN을 깊게 설계하게되면
어느 순간부터는 Image가 결국 1x1크기로 줄어들어 특징이 아예 소실되는 경우가 생길 것이다.
따라서 Convolution Layer를 통과할 때, Image 크기가 줄어들지 않도록 Padding이라는 방법을 사용하게된다.
영상처리에서도 Convolutional Kernel을 이용해서 원 Image에 Convolution할 때, 최외곽에 닿을 경웨 이미지 외곽부분은 모두 0으로 처리하는 방법을 주로 사용하는데,
이러한 방법을 Padding이라고 한다. Padding의 종류에는 Zero Padding(최외각을 모두 pixel 0으로 설정)과 Same Padding(최외곽을 모두 이미지 외곽의 pixel 값으로 사용)이 있다.

Stride
Stride란 Receptive Field를 원 이미지에 적용할 때, 한 작은 image patch를 연산하고 다음 연산 영역을 몇 pixel 건너뛸꺼냐에 대한 것이다.
* 이미지를 복원시키는 유형의 최신 논문에서는 이러한 stride으로 인해 Checkerboard Artifacts라는 현상 때문에,
(receptive field를 image를 convolution할 때, 겹치는 영역으로 인해 역 콘볼루션시 체크박스형태의 pixel이 보이는 현상)
deconvolution(역 콘볼루션) 기법을 잘 사용하지 않고, upsampling을 주로 하는 추세이다.

Convolutional Layer를 통과해서 나오는 Feature Map의 Size
Notation.
H : Height
W : Width
pad : Padding
K : Receptive Field (Kernel)
S : Stride

6. Pooling
Pooling은 CNN을 통과하고 나온 Feature Map에서 데이터의 대표적인 표현은 추출하면서 데이터의 양(크기)는 줄기는 기법이다.
Pooling의 방법에는 Average Pooling이 있고 Max Pooling이 있다.
아래 그림은 CNN을 통과하고 나온 Image를 Max Pooling하는 모습을 도식화 하였다.
그림을 보면, 빨간색 영역에서 제일 큰 숫자를 추출하여 하나의 pixel값을 만들게 되는데 이게 바로 Max pooling이다.
빨간 영역의 평균값을 구해 추출하게 되면, 이게 Average Pooling이 된다.
이런 Pooling도 Stride에 따라 결과값이 다르게 나올 수 있다.
일반적으로 Pooling하는 부분을 Pooling Layer라고 한다.

7. Visualization
뉴옥대에서 박사학위를 받고 2013년 Clarifai를 세운 Matthew Zeiler는 뉴옥대를 다니는 동안, CNN을 잘 이해할 수 있는 Visualization기법을 최초로 개발했으며,
2011년에 "Adaptive Deconvolutional Networks for Mid and High Level Feature Learning"을 논문을 발표했다.
이후 2013년에 "Visualizing and Understanding Convolutional Networks"이라는 유명한 논문을 발표했다.
CNN을 학습 시킬 때, 특히 layer가 여러개인 경우에에 어떤 원리로 그렇게 좋은 결과를 낼 수 있는지,
CNN의 구조를 결정하는 hyper - parameter는 어떻게 설정할 것인지 개발한 Network의 구조는 좋은지
나쁜지 판가름하기가 매우 어려웠다.
일반적으로 AlexNet의 경우 GPU 2개를 이용하여 학습하는데, 일주일 이상이 걸리는데, 10개가 넘는 hyper-parameter의 조합 중 최고를 찾아내는게
과연 가능할까?
Deep Neural Network가 좋은 결과는 있으나, 이론적으로 설명하기 어렵고, 최적인 구조인지 확인할 수 없기 때문에, CNN을 잘 이해할 수 있는
수단이 필요했다.
Matthew Zeiler는 ZFNet이라는 것을 사용하여 Convolutional Layer를 거치고, Pooling을 거친 결과의 Image를 다시 거꾸로
역 Pooling과 역 Convolutional Layer (DeConvolutional)를 통해서 시각화하고, 이를 관찰함으로써 학습시킨 CNN기반의 Network가 잘 학습이 되었는지 안되었는지
판가름하는데, 효과적임을 증명하였다.
해당 포스팅에서는 ZFNet을 소개하는게 중요한 것이 아니라, CNN을 학습시키고, 이를 Deconvolutional 한 결과를 보는 것을 통해서 우리가 CNN이 어떻게 작용하는지
이해를 도울 수 있기 때문에, Visualization의 결과를 소개하려고 한다.
Visualization의 결과는 다음과 같다.



8. Backpropagation
CNN의 Back-propagation은 기본적으로 Fully Connected Neural Network에서 시작한다.
Fully Connected Neural Network의 Back-propagation의 기본 수식 4가지는 다음과 같습니다.
8-1. Backpropagation of Fully Connected Neural Network









8-2 Backpropagation of Convolutional Neural Network
예제 이미지
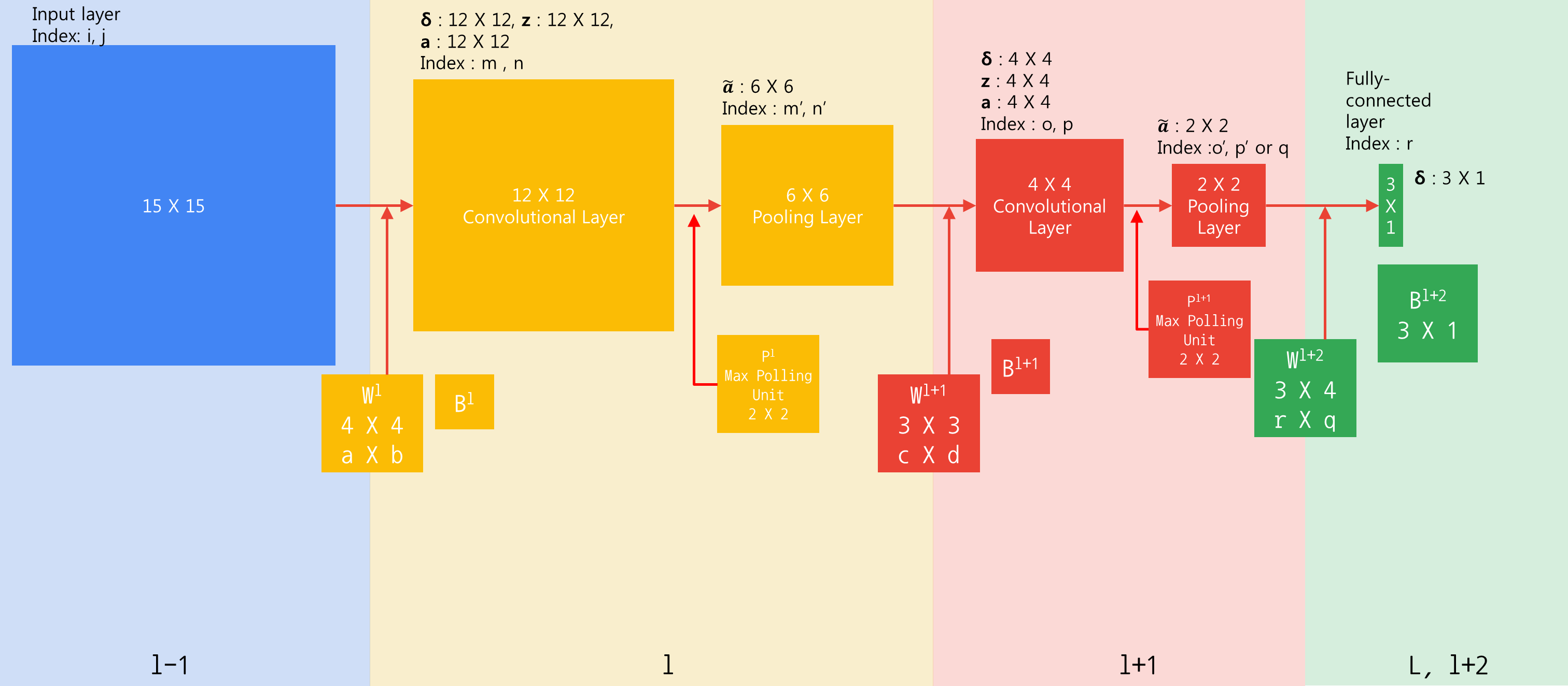
- 15X15 크기의 입력층으로 시작한다.
- 4X4 필터를 통해 12X12 크기의 출력을 생성한다.
- 2X2 크기로 Max Pooling하여 6X6 크기의 출력을 만든다.
- 3X3필터를 통해 4X4 크기의 출력을 생성한다
- Max Pooling을 통해 2X2 출력을 만든다.
- 2X2와 3X1이 완전히 연결되어있는 Fully Connected Neural Network가 있다
- 입력과 필터의 채널은 1이다.
- 필터는 하나만 사용한다.
- Stride는 1이다.
컨볼루션과 코릴레이션
1. 코릴레이션

2. 콘볼루션

여기서 둘의 차이는 코릴레이션은 F를 그냥 곱하고, 콘볼루션은 F를 180도 위상 반전시킨다는 차이가 있다.
일반적으로 CNN이 구현되어있는 Tensorflow, Caffe, Torch, Keras, CMTK등등 여러 프레임 워크에서 CNN을 계산하는 방식이 다르다.
그냥 코릴레이션을 쓰는 경우가 있고, 내부적으로 콘볼루션(180도 위상반전)하는 프레임워크가 있는데, CNN에서는 이 둘의 차이가 크게 다르지
않기때문에 이번 포스팅에서는 그냥 코릴레이션을 통해서 진행하겠다.
단계별 역전파
먼저 해당 공식에 대해서 숙지를 하고 넘어가겠다.
- CNN의 l번째 CONV층에서 가중합 코릴레이션 공식

- CNN 마지막 레이어에 있는 Fully Connected Layer의 가중합 공식

- 활성값 공식

이제 본격적으로 단계별로 역전파 과정을 살펴보자
단계1. 네트워크를 피드포워드(Feed Forward)한다. 단순 계산의 연속이기 때문에 어려운 부분이 없어서 생략하도록 하겠다.
단계2. Fully Connected Layer의 역전파 공식을 사용하여 출력층의 


단계3. 원래 역전파 알고리즘은 모든층의
편의상

→ b값은 통상적으로 1을 갖고, b에 대한 weights값을 갖는데, b를 weights값으로 치환할 수 있다.


Note. CONV의 마지막 레이어의 2X2출력은 다음과 같이 표현할 수 있습니다.
→ 따라서 Fully Connected Layer의 역전파처럼 





단계4. 이제





CONV 층의 학습 변수이므로 Fully Connected Layer와 연결 양상이 다르다.
즉,
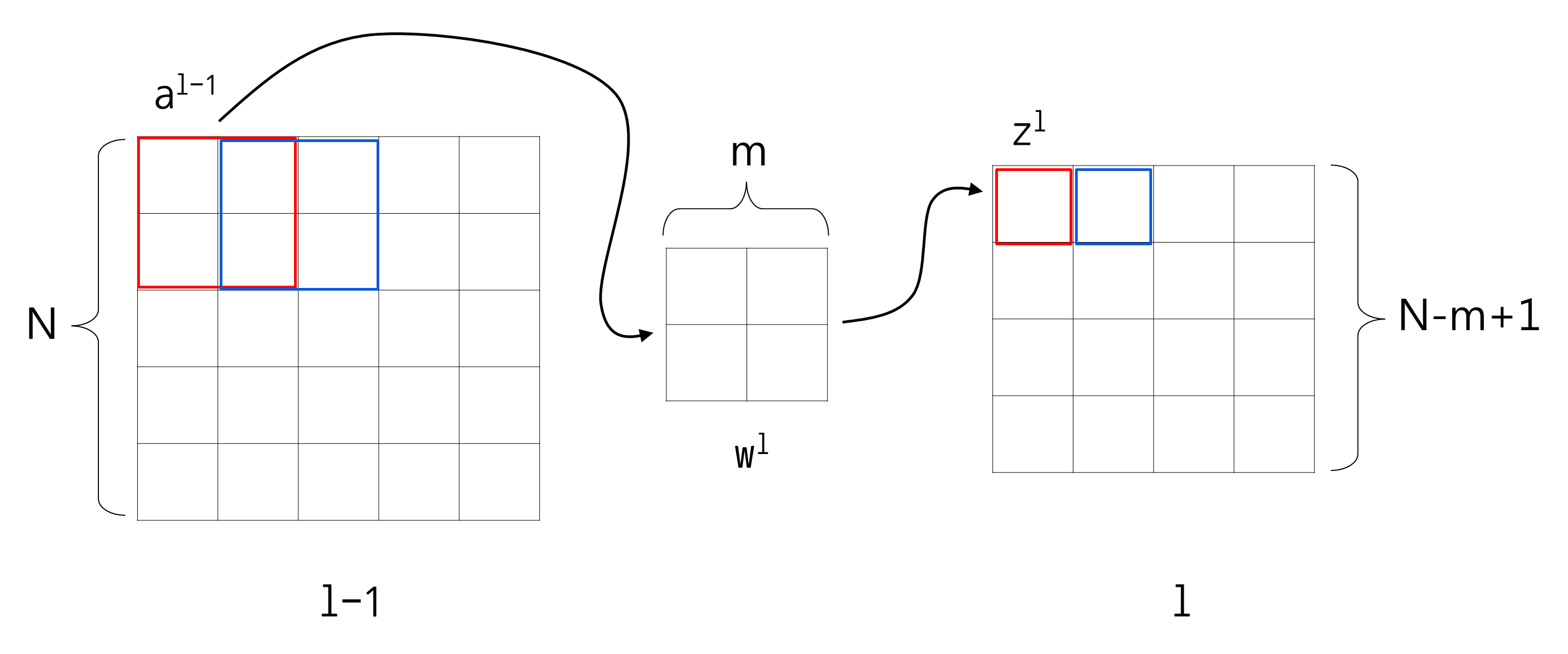





CONV 모델이다. 코릴레이션 공식을 인덱스를 변경해서 표현해보면 다음과 같다.

이제

위 식에서

가 된다. 기존 Fully Connected Layer의 Back propagation과 비교해보면, CONV층에서 
따라서 최종 수식은 다음과 같이 된다.

위 식에서 N: l-1번째 층의 가로 세로 크기, m: 필터 w의 가로 세로 크기이다.
이제 

위 식에서 

따라서 식을 다시 써보면 다음과 같이 표현할수 있다.

해당 식은 l-1번째 층 활성값 

기존 Back propagation은

따라서

위 식에서 N: l-1번째 층의 가로 세로 크기, m: 필터 w의 가로 세로 크기이다.
여태까지 수식에서 봤듯이 입력층과 필터의 모양이 꼭 정방형일 필요가 없음을 알 수 있다.
이제 남은 것은


CNN 모델에서 

체인룰을 적용하면 다음과 같다.

여기서 

위의 식에서
따라서

이를 기존의 Fully Connected Layer의



Pooling과 Pooling의 역전파는 아래의 그림과 같다.
Max Pooling은 같은 바운더리안에서 최대값을 Average Pooling은 바운더리의 평균값을 전파하게된다.
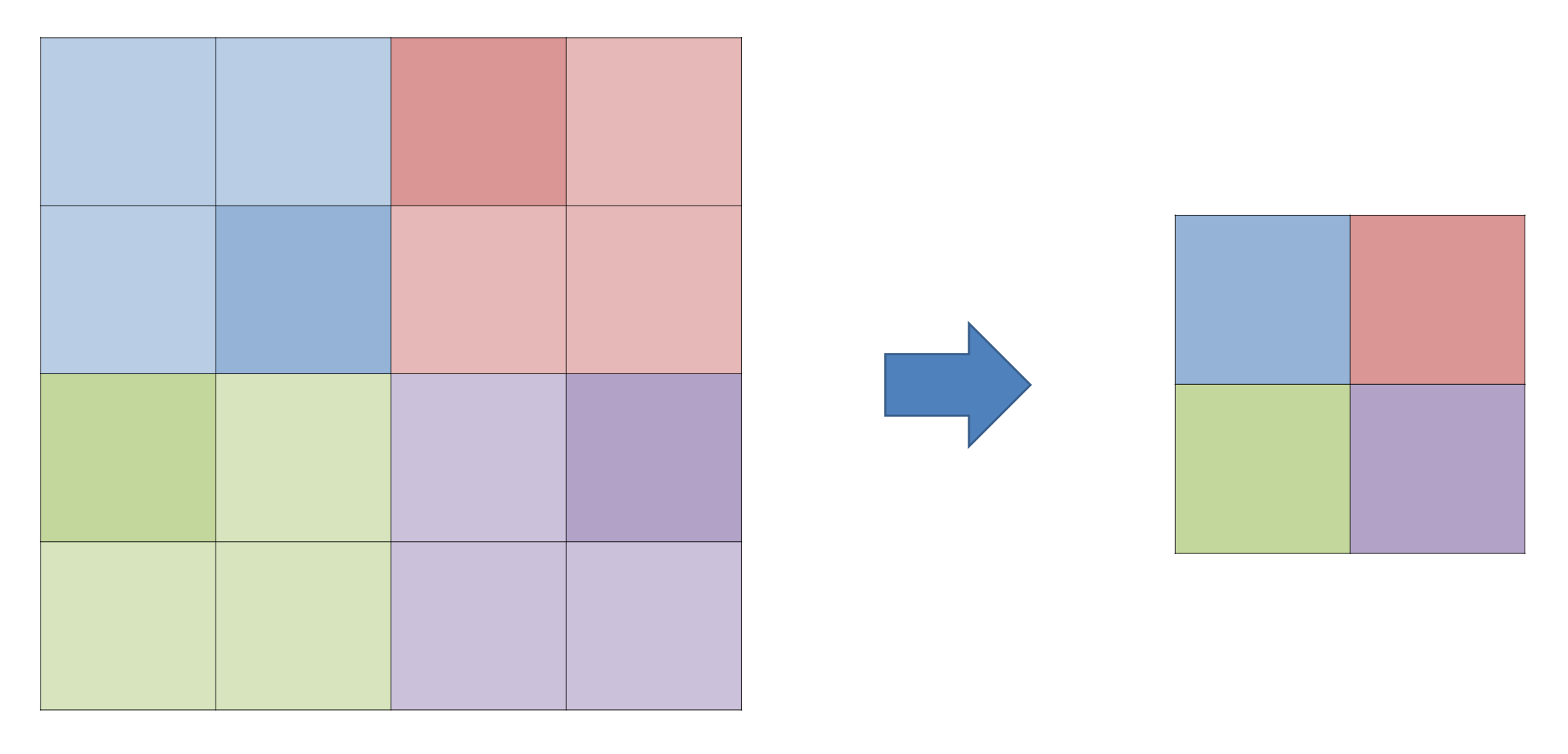
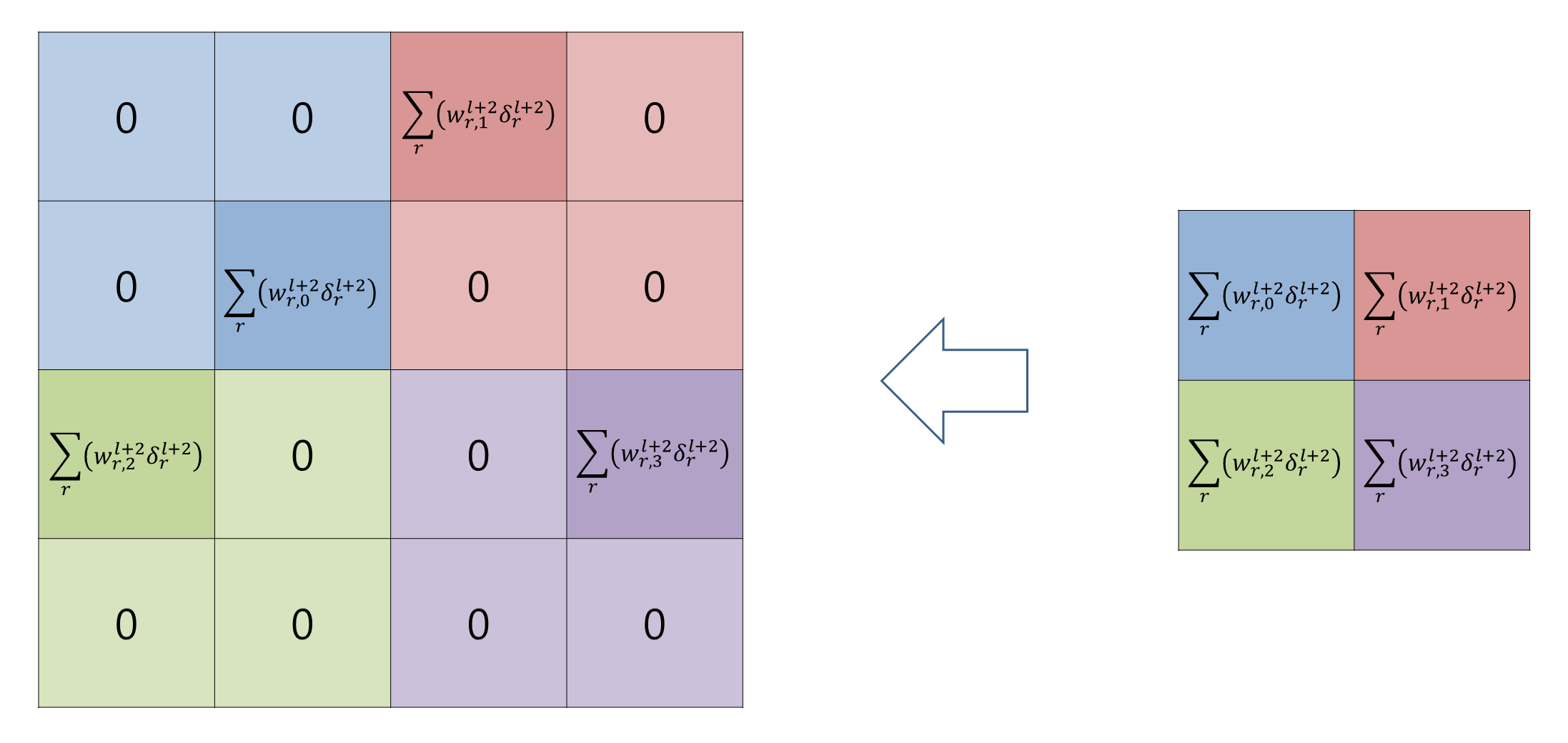
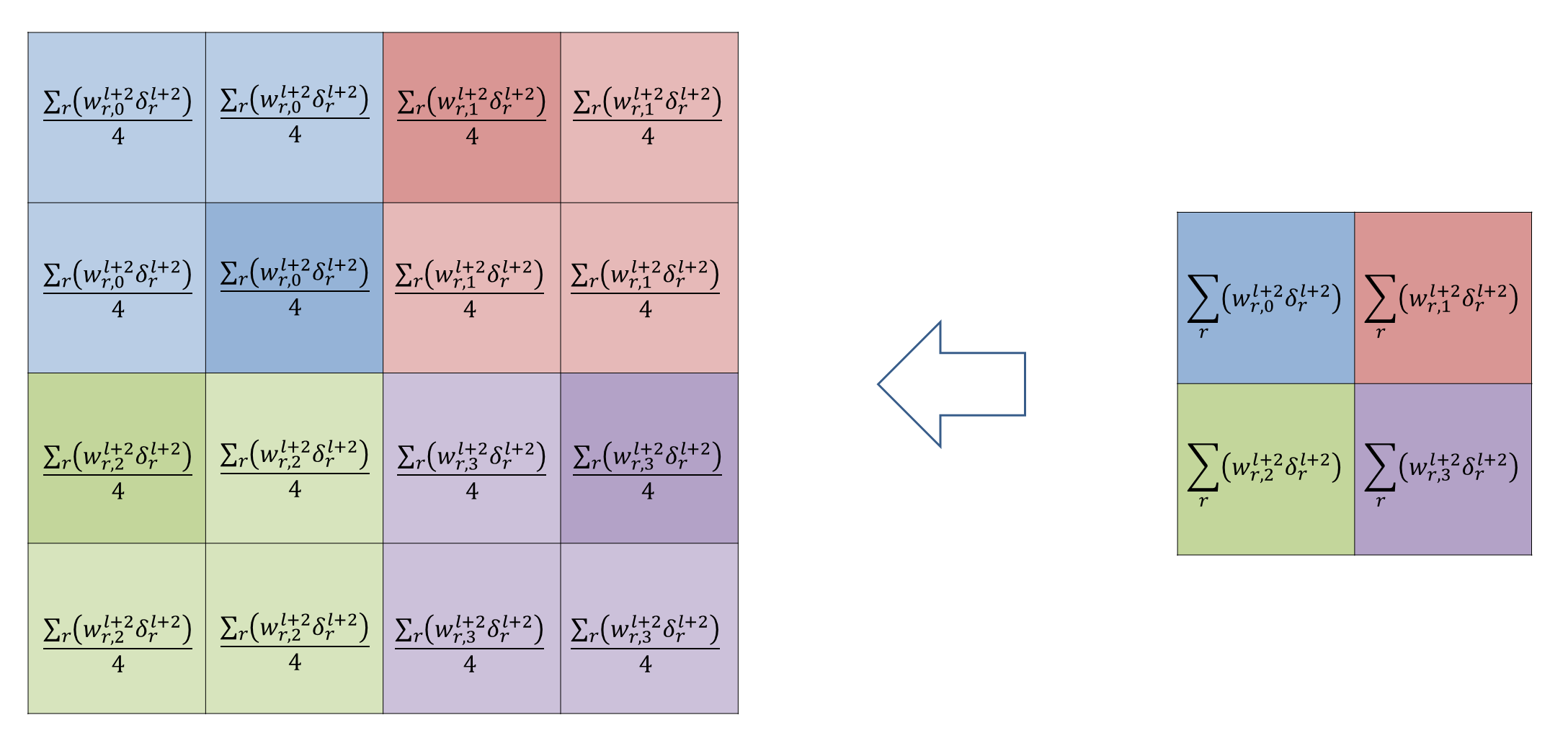
위와 같이 특정 위치로 경로를 지정해서 값을 보내주는 것과 같은 형태로 오차 역전파가 일어나게 되며,
Max Polling의 경우에는 Gradient Route, Average Pooling의 경우에는 Up-sampling이라고 한다.
9. Reference
- 기계학습(Machine Learning) - Class 19: Neural Network의 " CNN(Convolutional Neural Network)"
- 기계학습(Machine Learning) - Class 20: Neural Network의 " Why CNN(Convolutional Neural Network)"
- 기계학습(Machine Learning) - Class 21: Neural Network의 " CNN(Convolutional Neural Network)의 구조?"
- 기계학습(Machine Learning) - Class 22: Neural Network의 " CNN(Convolutional Neural Network) - Convolutional Layer Part 1"
- 기계학습(Machine Learning) - Class 24: Neural Network의 " CNN(Convolutional Neural Network) - Convolutional Layer Part 2"
- 기계학습(Machine Learning) - Class 29: Neural Network의 " Best CNN(Convolutional Neural Network) Architecture - ZFNet(Part1)"
- 딮러닝 - 콘볼루셔널 네트워크를 이용한 이미지 인식의 개념
- CNN 역전파를 이해하는 가장 손쉬운 방법
- 컨볼루셔널 뉴럴넷
- CNN 초보자가 만드는 초보자 가이드
- CNN의 직관적 이해
- [딮러닝/영상처리] Convolution & Correlation 이해하기
- What does stride mean in the context of convolutional neural network?
- Convolutional Neural Networks - What is done first? Padding or convolution?
- Artificial Inteligence
- CS231n Convolutional Neural Network for Visual Recognition
- Deconvolution and Checkerboard Artifacts
'IT > Deeplearning' 카테고리의 다른 글
| [Performance Measurement] Precision/Accuracy (2) | 2017.10.19 |
|---|---|
| [번역:: Gradient Clipping] Why you should use gradient clipping (0) | 2017.10.15 |
| [MLP::Multi Layer Perceptron] Swallow Neural Networks :: Fully Connected Layer (1) | 2017.10.13 |
| [Material] 비숍의 패턴인식과 머신러닝 (0) | 2017.10.13 |
| [YOLO DARKNET] 구성 및 설치, 사용방법 (0) | 2017.06.04 |


